

Data Visualization
Data Science
AI
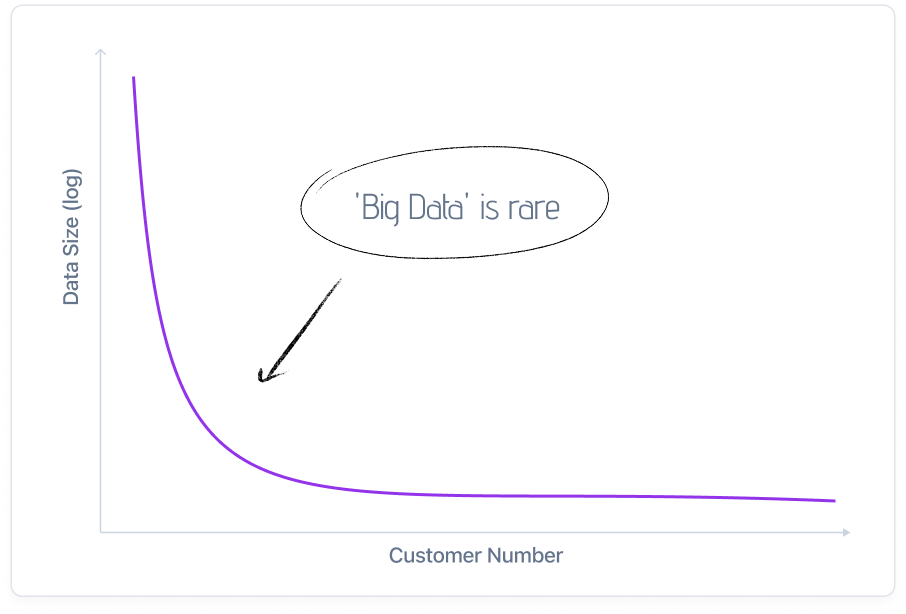
For over a decade, ‘Big Data’ has been a buzzword in the tech industry, often hailed as a panacea for many business challenges. However, as Jordan Tigani, a former Google BigQuery engineer, suggests, the significant data era might be overstated, if not entirely redundant, for many. This article explores why the allure of big data may be a misdirected pursuit for most businesses and organizations.
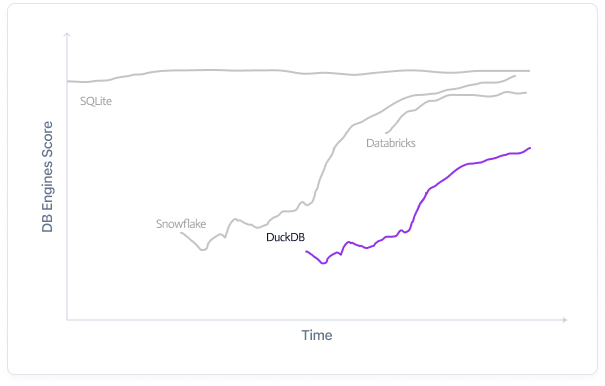
Pure NoSQL systems for OLAP are stagnating relative to traditional data management systems because traditional systems slowly expanded support for NoSQL “Not Only SQL” (not “No” SQL) capabilities. The “next generation” SQL or replacement to the “Old Tried and True” never panned out. SQL remained. But that doesn’t mean improvements have not been made. MongoDB gained widespread adoption, and a variety of wide, narrow, and specialized table formats have proliferated. Yet, SQL persisted.
Now, we have newcomers like DuckDB to reimagine the basics with optimized data formats and storage and a Duck-friendly SQL. SQL will continue to exist for the foreseeable future. Still, we also deserve a better one, given the ubiquity of data formats like Apache Arrow and Apache Iceberg to help standardize data warehousing and analytics storage.
The idea behind the “Big Data is coming” narrative was clear: soon, everyone would be drowning in data. However, ten years on, that prediction hasn’t panned out. Most organizations aren’t overwhelmed by data volume, they’re overwhelmed by what to do with the data they already have. Both quantitative data and qualitative insights, as well as first-principle reasoning, confirm this reality. Most businesses still struggle to contextualize their data, and data teams often struggle to tell clear, actionable stories from it. No one is happy.
Data Sizing Insights from the Fortune 5 (at the time…)
I analyzed customer data usage extensively at Fortune 5 to 100 Companies in both Healthcare and Finance. While I can’t share exact figures, I can highlight some trends. Most clients we worked with had less than a few TBs of total data storage.
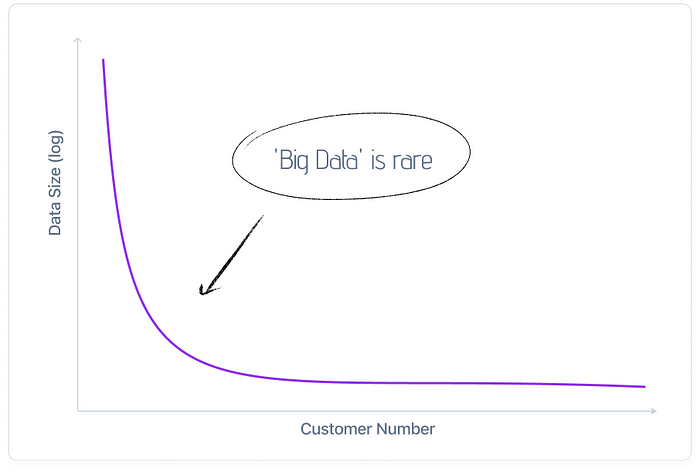
While some internal organizations stored large amounts of data, the majority, including many large data teams, had relatively moderate data sizes in the GBs.
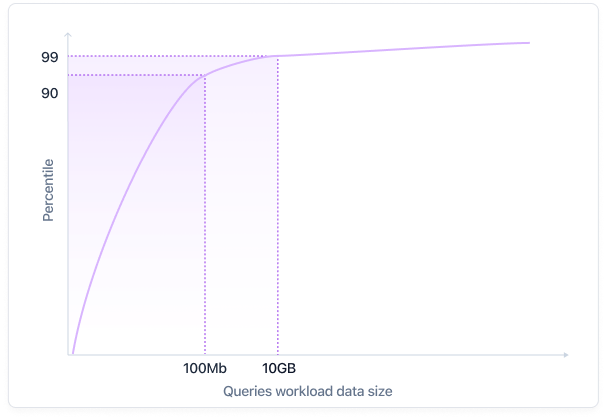
We certainly subscribed to many expensive data sources. We did not use them extensively, or they lacked “good data” that was worth integrating.
In reality, compute needs do not stay fixed over time—they vary from day-to-day workload to workload. Yet many architectures are optimized for scaling storage, not compute flexibility. Flexibility in both data size and computing dimensions is key.
We over-prepare for growing data volumes and under-prepare for compute variability.
While recent data is queried more, plenty of mission-critical needs require querying all of the data.
More modern servers can handle “big data” by themselves, but keeping them provisioned with throughput can be pretty expensive, as opposed to scaling up and down lower-cost machines in a cluster on demand.
As data becomes easier to store, it also becomes harder to secure, and data is no longer just an asset; it’s a liability. In today’s Cybersecurity landscape, it is natural to understand that it is not a matter of “if” you get hacked but “when.” How can you minimize exfiltration, ransomware, or other data extortion and security concerns? PII data goes for pennies on the dollar now, but PHI a lot more. The better path is to treat data retention with intention. Minimize exposure, encrypt selectively, and ask whether the data you’re storing is truly worth the risk.
One way to think about the difference between big and small/medium data tools is to compare scuba diving to snorkeling.
What scuba and snorkeling have in common is that they are both enjoyable water activities. When you wear scuba gear, you can stay near the surface or go deep. When you wear a snorkel, you have to stay near the surface. Scuba gear is a complete replacement for a snorkel and provides functionality beyond it. Some might say scuba gear is cumbersome, but for most people who’ve tried both, scuba diving is a lot more pleasant and rewarding than having to return to the surface frequently! Basically, why just stay on the surface when one can dive in?
Similarly, sometimes one needs to go deep with one’s data, and sometimes one wants a surface-level insight — it’s best to use a tool that lets you do both.
Customers with giant data sizes almost never queried huge amounts of data
Most organizations that collect data have needs that range from small to big data sizes, and from small to large compute requirements, on a day-to-day and query-by-query basis. Being flexible to varying organizational needs is paramount.
A better framing is to focus on the tools, not the data. It shouldn’t matter if you are in the 99% or the 1% of data sizes: We should help users get the insights or build the models that they need from the tools they want to use, regardless of data size. Sometimes you want a quick-and-dirty superficial insight, sometimes you want to dive deep into the past: The best tools let you do both without requiring a change in workflow.
Jordan Tigani’s transition from a Big Data proponent to a skeptic is a telling narrative in the tech industry. Despite the common perception, most companies do not handle data volumes that justify the ‘big data’ label. As Tigani discovered, the real picture shows many enterprises handling data well below the terabyte threshold. This revelation dismantles the one-size-fits-all approach that has been ubiquitously sold to businesses.
The separation of storage and computing in modern cloud data platforms has been a game-changer. However, the practical application of this separation reveals that most businesses do not require the massive computing resources often associated with big data. This misalignment between perceived and actual needs leads to inefficient resource allocation and inflated costs.
Jordan Tigani’s analysis of BigQuery queries revealed a crucial insight: the majority of data workloads are considerably smaller than the total data stored. This disparity suggests that large-scale big data solutions are often an overkill for the actual processing needs of most companies.
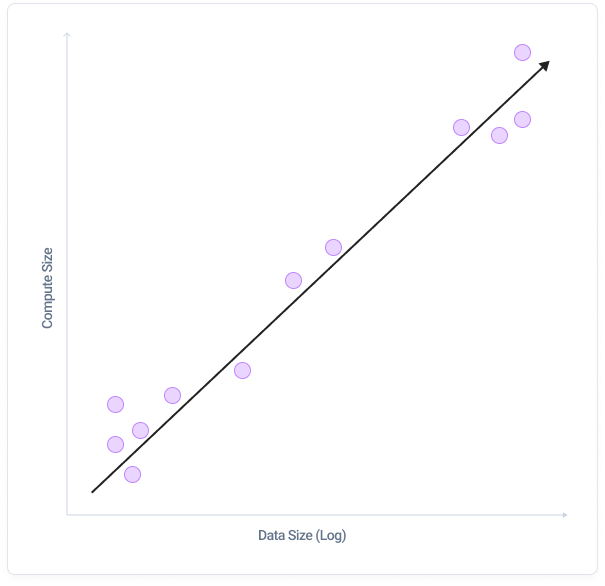
Contrary to the belief that all stored data is regularly queried and analyzed, the reality is starkly different. Most data, especially as it ages, is rarely accessed. This understanding challenges the rationale behind maintaining extensive big data processing capabilities, which are seldom utilized to their full extent.
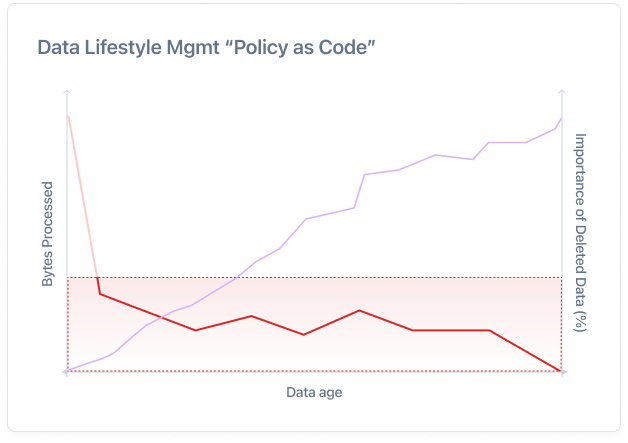
MotherDuck said it best when Jordan Tigani said, “Big Data is Dead.” In the original article [https://motherduck.com/blog/big-data-is-dead/ ]. datajoi agrees. datajoi builds on that idea to apply data visualization and analysis, auto-magically.